Sentiment analysis in large volumes of text data

The current tendency text to everything that is being incorporated by AI generative models reveals that the principal way of communication in the digital era is writing. Therefore, the majority of the data that we create is unstructured, which means that it is difficult to analyze and extract meaningful insights. This is where text mining and NLP come in. These tools allow us to extract valuable insights and patterns from large volumes of text data. Companies can use these tools to analyze customer feedback, social media data, news articles, form responses, and other kinds of unstructured data to obtain valuable information about their customers’ preferences, opinions, and behaviors.
Here we show an example of sentiment analysis, one of the main techniques of NLP for determining the emotional tone of a text. Then, we can identify the polarity of the text and how it is perceived. Specifically, we analyze the differences of language and style in 3 books of fantasy literature available on Project Gutenberg:
- The Divine Comedy by Dante Alighieri (1320)
- Gulliver’s Travels by Jonathan Swift (1726)
- Alice’s Adventures in Wonderland by Lewis Carroll (1865)
First, I prepare the data, creating line numbers, tokenizing the text, and removing stopwords of each book:
fantasy <- gutenberg_download(c(8800, 829, 28885), meta_fields = 'author')
tidy_fantasy = fantasy %>%
mutate(author = str_replace(author, ", | ", "_")) %>%
group_by(gutenberg_id) %>%
mutate(linenumber = row_number(),
chapter = cumsum(str_detect(text,
regex("^chapter|^CANTO [\\divxlc]" ,
ignore_case = TRUE)))
) %>%
ungroup() %>%
unnest_tokens(word, text) %>%
anti_join(stop_words) %>%
mutate(word = str_extract(word, "[a-z']+"))
tidy_fantasy
| gutenberg_id | author | linenumber | chapter | word |
|---|---|---|---|---|
| 829 | Swift_Jonathan | 229 | 1 | shore |
| 829 | Swift_Jonathan | 229 | 1 | country |
| 829 | Swift_Jonathan | 229 | 1 | lilliput |
| 829 | Swift_Jonathan | 229 | 1 | prisoner |
| 829 | Swift_Jonathan | 230 | 1 | carried |
| 829 | Swift_Jonathan | 230 | 1 | country |
| 829 | Swift_Jonathan | 233 | 1 | father |
| 829 | Swift_Jonathan | 233 | 1 | estate |
| 829 | Swift_Jonathan | 233 | 1 | nottinghamshire |
| 829 | Swift_Jonathan | 234 | 1 | sons |
Then, I use the lexicon “Bing” to assign a sentiment to each word, joining it with our dataframe. We counted positive and negative words in 80-line chunks, and pivoted to wide format, so that each sentiment has its own column. Finally, we create a column to give an overall sentiment score to each chunk:
fantasy_sentiment = tidy_fantasy %>%
inner_join(get_sentiments("bing")) %>%
count(author, index = linenumber %/% 80, sentiment) %>%
pivot_wider(names_from = sentiment, values_from = n, values_fill = 0) %>%
mutate(sentiment = positive - negative)
fantasy_sentiment
| author | index | negative | positive | sentiment |
|---|---|---|---|---|
| Carroll_Lewis | 0 | 16 | 13 | -3 |
| Carroll_Lewis | 1 | 13 | 4 | -9 |
| Carroll_Lewis | 2 | 20 | 8 | -12 |
| Carroll_Lewis | 3 | 22 | 14 | -8 |
| Carroll_Lewis | 4 | 18 | 9 | -9 |
| Carroll_Lewis | 5 | 22 | 10 | -12 |
| Carroll_Lewis | 6 | 23 | 10 | -13 |
| Carroll_Lewis | 7 | 22 | 11 | -11 |
| Carroll_Lewis | 8 | 14 | 9 | -5 |
| Carroll_Lewis | 9 | 13 | 3 | -10 |
Then we plot the sentiment distribution of the texts:
ggplot(fantasy_sentiment, aes(index, sentiment, fill = author)) +
geom_col(show.legend = TRUE) +
facet_wrap(~author, ncol = 1, scales = "free_x")+
labs(title="Sentiment score by Author", y="Sentiment Score", x="Index") +
scale_fill_manual(values = c("#df539b", "#b249ae", "#5d3195")) +
theme_minimal() +
theme(
legend.position = "none",
plot.title = element_text(face = "bold"),
panel.background = element_rect(fill = "white"),
plot.background = element_rect(fill = "white")
)
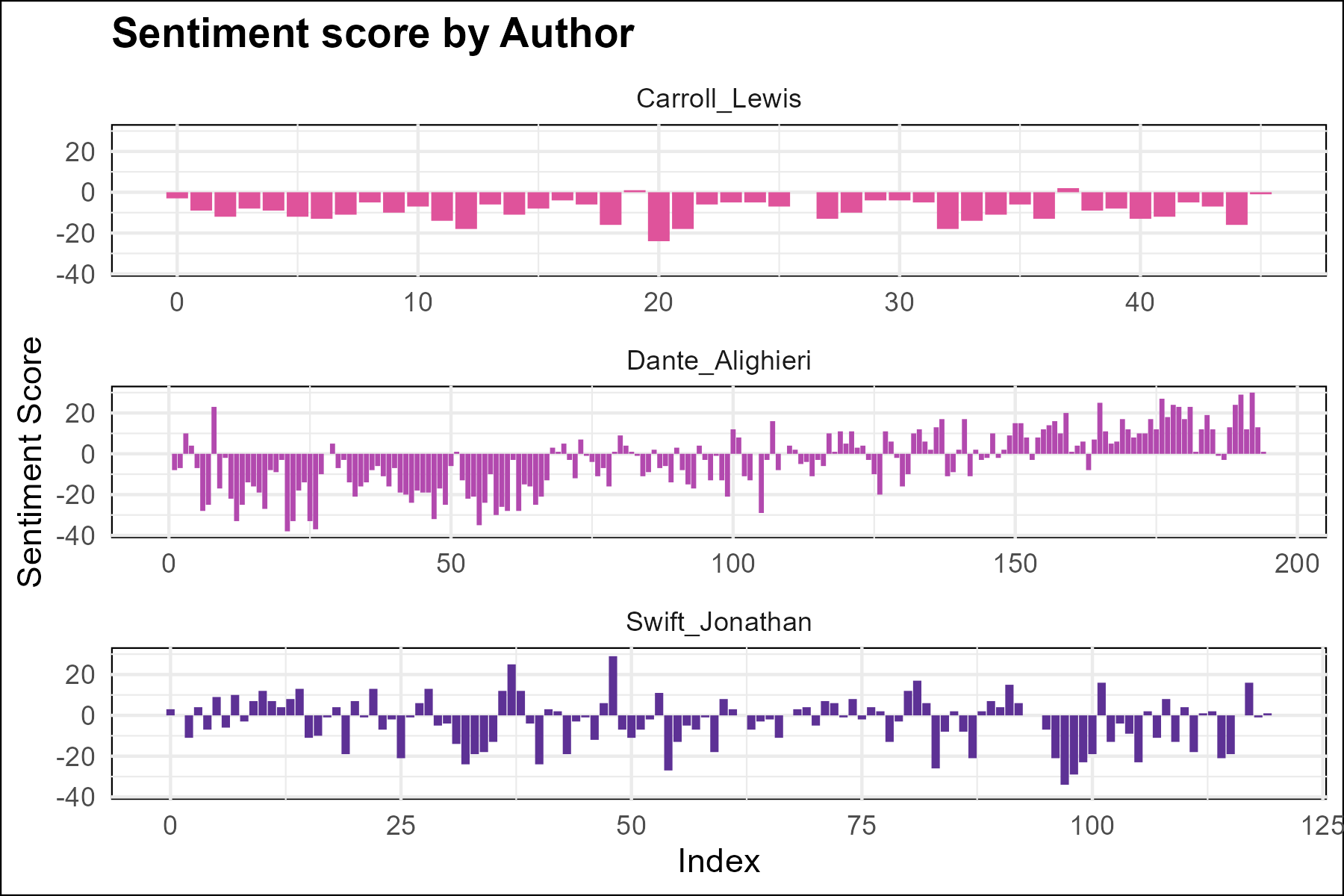
We identify trends and patterns in sentiments that reflect the content of each book.
-
In the Divine Comedy, we notice a strong trend from negative sentiments to positive sentiments. This quite matches the chronicle that starts at hell, goes through purgatory, and then arrives to the heaven. The language expresses the suffering, pain, and desolation of hell, and the tranquility, fullness, and blessedness of heaven. The sentiment distribution captures this metaphysical travel.
-
In Alice in Wonderland, in contrast, the whole text is classified as negative. It would represent the critical expressions, events, or emotions contained in the text or that the sentiment lexicon is biased. Throughout the book, Alice travels through a surreal world full of strange and unfamiliar places, such as the Mad Hatter’s tea party, the Queen of Hearts’ castle, and the Cheshire Cat’s forest. These places can be confusing, disorienting, and even frightening, which can evoke negative emotions. Additionally, the characters in the book often display negative emotions, such as anger, frustration, and fear. The Queen of Hearts, in particular, is known for her temper and her penchant for ordering beheadings, which can create a negative and tense atmosphere.
-
Gulliver’s Adventures appears to be a combination of previous books. It combines positive and negative sections, depending on the section analyzed. While in some parts, there are many humorous and absurd situations that can evoke a sense of joy and lightheartedness, other sections involve political intrigue and betrayal, which can create a sense of tension and negativity. This is the kind of book with high complexity and a variety of emotions.