Scraping coral reef data from a JS website

Web scraping is a powerful tool for data extraction and analysis. This innovative technique involves using specialized software to gather and process data from websites, social media platforms, and other online sources. So why is web scraping so useful? For starters, it enables us to collect and analyze large amounts of data quickly and efficiently. With a web scraper, you can gather information from multiple sources, and compile it into a single dataset for different purposes, such as market research, lead generation, social media monitoring, and content aggregation.
But that’s just the tip of the iceberg when it comes to the benefits of web scraping. One of the most significant advantages of using a web scraper is its ability to gather data from sources that don’t have an API available, or when the data you need is not open in a public database or not formatted in CSV files.
Gathering data from ReefBase
ReefBase is a data repository that provides access to information on coral reefs around the world. It was created by the international organization WordlFish Center, to ease the monitoring and analysis of coral reef health and the quality of life of reef-dependent people. However, it had a small issue, there were no data download options. The solution to taking advantage of such a great online repository was to create a web scraper that extracts reef and marine data from different countries. This is our page of interest:
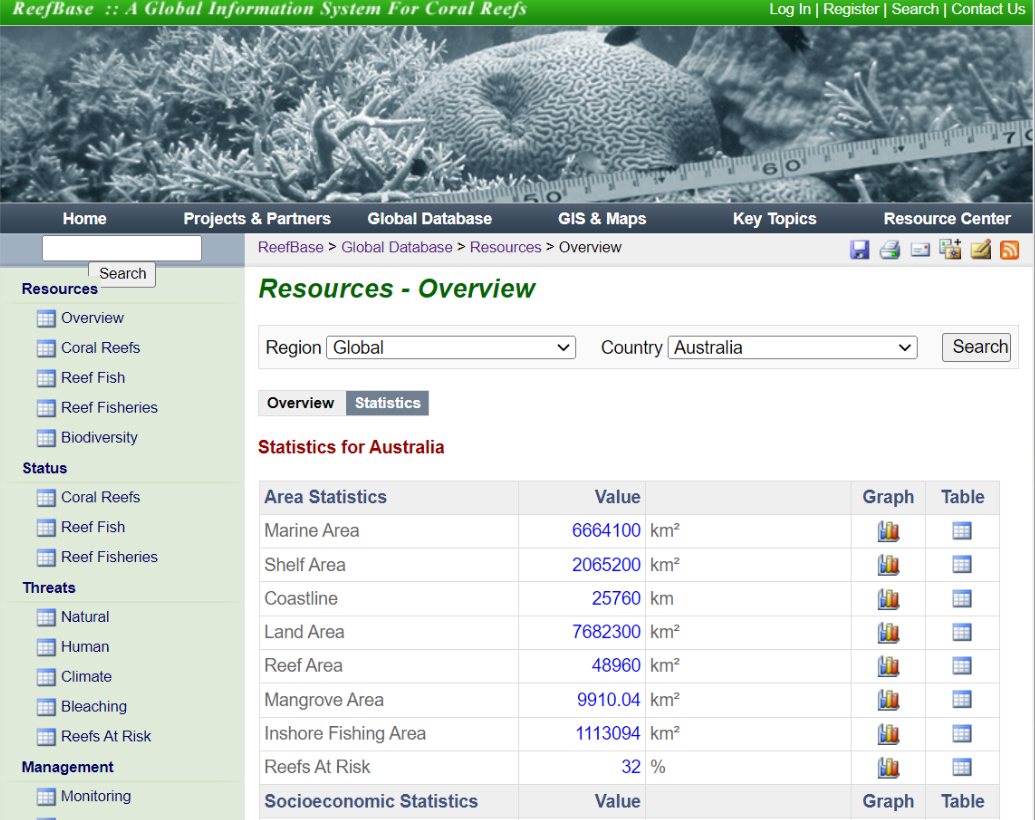
The main characteristic is that ReefBase is a JavaScript website that allows users to interact with the interface to search across the repository. For example, users can search by region or country, using dropdown menus. Due to this fact, I used Selenium to create a bot that mimics human interaction with the web page to locate specific elements on the page, select options from the dropdown (each country), and click on the search button. Then, the program dives automatically through the reef data for each country, and downloads the information that we need.
The result is amazing! First, let’s see this video where we show how the bot works. Look at how the dorpdown and the data change after each iteration. After that, I show how I built the scraper.
full_data = data.frame()
for (j in seq_len(n_countries)){
print(j)
if(j == 1 | j == 39 | j == 46 | j == 63 | j == 94 | j == 112 | j == 123) {next}
xpath = paste0("//td//select[@name = 'ctl00$Content$cboCountry']//option[", j, "]")
Sys.sleep(2)
driver$findElement(value = xpath)$clickElement()
Sys.sleep(2)
driver$findElement(value = '//div/input[@type = "submit" and
@name="ctl00$Content$btnAdvancedSearch"]')$clickElement()
page_source <- driver$getPageSource()[[1]]
all_tables = page_source %>%
read_html() %>%
html_table()
data <- all_tables[[143]]
colnames(data) = tolower(data[1, ] )
data[-1,]
data = data %>%
rename(area_statistics=1, unit=3) %>%
select(!c(graph, table)) %>%
mutate(value = as.numeric(value),
ctr_code = j)
full_data = full_data %>%
rbind(data)
}
Once we had a dataframe with the reef information by country, some cleaning was applied, and the result is a dataset ready for analysis and visualization:
| country | Marine_Area | Shelf_Area | Coastline | Land_Area | Reef_Area | Reefs_ At_Risk |
|---|---|---|---|---|---|---|
| Australia | 6664100 | 2065200 | 25760 | 7682300 | 48960 | 32 |
| Bahrain | 8000 | 10000 | 161 | 665 | 760 | 82 |
| Bangladesh | 39900 | 59600 | 580 | 130168 | 50 | 100 |
| Barbados | 48800 | 320 | 97 | 430 | 90 | 100 |
| Belize | 12800 | 8700 | 386 | 22806 | 1420 | 63 |
| Brazil | 3442500 | 711500 | 7491 | 8459417 | 1200 | 84 |
| Colombia | 706100 | 16200 | 3208 | 1038700 | 2060 | 44 |
| Costa Rica | 542100 | 14800 | 1290 | 51060 | 30 | 93 |
| Dominican Rep | 246500 | 5900 | 360 | 48320 | 1350 | 89 |
| Egypt | 185300 | 50100 | 2450 | 995450 | 3800 | 61 |